 |
Hardware Architectures for Machine LearningHardware choices for machine learning include CPUs, GPUs, FPGAs, and ASICs. Currently CPUs are used in inferencing tasks while most training is done mostly using GPUs. Our work consists of devising hardware architectures that match the computational, memory, and connectivity demands of emerging ML applications. We focus on characterization of ML workloads, bottleneck identification, and architectural enhancements. Recent contributions include a reconfigurable substrate for ML. |
 |
Cloud and Big Data ArchitectureAnalyzing massive amounts of data, deriving insight and seeing things one could not see before has become important for businesses, medicine, world economy and human life in general. It is important that next generation computer systems handle these analytics workloads efficiently. It is not known what kind of computing and network resources are needed for these applications. What kinds of cores, memory organizations and clustering support will be needed to support big data apps? What are optimal partitioning strategies other than simply using the available/affordable nodes? Are there code characteristics that can be tapped to decide on optimal partitioning considering performance, power, and energy tradeoffs? How do the compute and communication requirements scale depending on map slots? Are there special localized communications (fog computing as opposed to cloud) and buffering that can help? What will be the impact of an in-memory version of map-reduce as opposed to the traditional map-reduce where every communication goes through the file system? Our studies will attempt to answer these and like questions. Performance characterizations of map-reduce tasks will help to determine appropriate map-reduce configurations for the future. Understanding of emerging big data computing workloads is required in order to drive hardware and software development. We focus on workload characterization of big data and cloud workloads and design of high performance and energy-efficient architectures for them. |
 |
Memory Systems for Multicore and Many-core ArchitecturesAs microprocessors move from the multi-core to the many-core era, the Von Neumann memory bottleneck is becoming more critical. For instance, the SPARC server platform roadmap (2010 to 2015) projects a 32X increase in the number of threads in 5 years. To be able to leverage such abundant computing power, it is important to design efficient memory subsystems. We are currently looking at different memory configurations, hierarchies and data partitioning algorithms that can minimize the number of off-chip (or off-node) memory accesses and/or minimize the latencies observed by the processing unit. We are also investigating new structures to make the memory hierarchy efficient. One important ongoing research project is the i-MIRROR project that utilizes Hybrid Memory cube (die-stacked memory) integrated into the memory hierarchy. Selected regions from the main DRAM are mirrored into the die-stack using a software managed technique. Microarchitectural techniques to assist the operating system for efficient management of i-MIRROR are being investigated. |
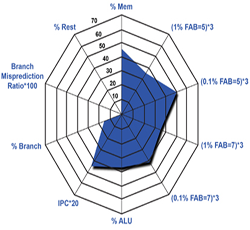 |
Workload CharacterizationWorkload characterization and identification of bottlenecks allows computer architects to design computer systems that yield high performance, energy-efficient operation and reliability. Our research group focuses on workload characterization of emerging application domains and emerging processor architectures. Understanding the nature of programs and the workload behavior leads to the design of improved computer architectures. In our past research, we developed methodologies to characterize applications at an abstract level, which allow us to identify the generic properties of the application in terms of its memory access behavior, locality, branch behavior, instruction level parallelism, etc. We also characterized multicore workloads to identify sharing and synchronization characteristics of multiprocessor workloads. Utilizing the abstract metrics of program behavior, a machine-independent program behavior model can be generated. In the past our workload characterization led to program similarity/dissimilarity studies and clustering techniques. The clustering techniques were used in benchmark selection and subsetting. Currently, we are working on emerging workloads including cloud computing, big data workloads, mobile and embedded workloads. |
 |
Proxies for Computer Performance/Power EvaluationModern high performance processors contain hundreds of millions of transistors, and are very complex. The designs of these processors contain millions of lines of VHDL or Verilog code. It is extremely difficult to perform pre-silicon estimation of performance and power of such designs for real-world workloads, however, without which, it is impossible to identify good design points early in the design process. Prior performance validation efforts have usually used handwritten micro-benchmarks that are too small to approximate the performance of real world workloads. Once validated using these tests, performance models still exhibit large errors on benchmarks like the SPEC benchmarks. Validation with full-blown benchmarks like SPEC will avoid post-silicon disappointments, however many of the SPEC benchmarks contain trillions of instructions and it is impossible to simulate them on RTL models. Sampling techniques can reduce trace lengths, but the executions still amount to hundreds of millions of instructions. In some of our past research, we demonstrated the usefulness of a workload synthesis philosophy to create miniature clones of SPEC and commercial benchmarks to validate processor models. Design and evaluation of future computer systems with large number of nodes comes with a variety of challenges. Full system simulation of these systems for emerging workloads such as cloud and big data workloads will be next to impossible. Miniaturized Proxy workloads that capture essential properties of these workloads can be created to simplify the performance evaluation problem. We are working on creating proxy workloads for big data and cloud workloads. Our research also includes creation of power, reliability and thermal stressmarks that help to identify guard-bands in design. Typically in the industry, these stressmarks are hand-coded by engineers intimately familiar with the design and architecture of systems. We develop automated procedures to develop benchmarks and stressmarks that test and validate modern computer systems from performance, power, energy, thermal and reliability perspectives. |
 |
Development of Energy-efficient, High-Performance CodesAmong the many hurdles faced in research and development of compute-intensive codes is achieving high performance and energy efficiency. Indeed, many codes often achieve less than 10% of the peak system performance. This problem has become more acute with the emergence of deeper memory hierarchies and many-core and heterogeneous architectures including GPGPU systems. We work with computational scientists to identify bottlenecks in their codes as they execute on modern computer systems. Algorithms created by computational scientists will be analyzed and optimizations to improve performance and energy-efficiency incorporated. We will perform thorough evaluations of high performance codes and will co-design the codes to explore alternative algorithm/hardware scenarios. Having identified the main bottlenecks and the most fundamental and effective primitives, we will co-design novel hardware mechanisms using enhancements to existing general-purpose heterogeneous platforms. |